|
I am a CS Ph.D at UCLA, co-advised by Prof. Yizhou Sun and Prof. Kaiwei Chang. Before coming to UCLA, I have spent a year in Moonshot.AI (one of the earliest core members), working as a founding research scientist working on LLM and VideoGen. I was the major contributor of pre-training large language models with extremely long context, leading to KIMI CHAT, achieving the state-of-the-art performance on many long context tasks compared with GPT4 and Claude2 at that time. I completed my bachelor's degree of Electronic Enginnering at Tsinghua University. I worked with Prof. Zhilin Yang from 2021 to 2023. My research interest lies broadly in scalable deep generative architecture and LLM reasoning. Most Recently, I am interested in (1) exploring scalable architectures and recipes for LLM/VLMs and multimodal generation as well as (2) studying the self-evolution paradigm of large foundation models. Feel free to contact me for chat or discussion if you are also interested in these topics. Email: lzyxx17 [at] gmail.com |

|
|
|
|
Research Intern, NVIDIA, 2025 • Core contributor of GROOT-N1, the first open foundation model for Generalist Humanoid Robots.
Research Intern, Apple, 2024 • Main contributor of STIV, a large videogen model, outperforming PIKA, GEN-3, KLING on VBench.
Research Scientist, Moonshot AI 2023, • Long-context scaling, videogen, main contributor of KIMI CHAT. Quant Researcher Intern, Ubiquant, Top Hedge Fund in China. 2022 Research Intern, Sensetime, China, 2021 |
|
My research interest lies broadly in natural language processing and general machine learning. Most Recently, I am interested in (1) exploring scalable architectures and recipes for LLMs / VLMs and multi-modal generation; (2) improving the self-evolution of LLMs / VLMs; (3) improve better alignment with the physical world for vision generative models and vision language models |
|
| |

|
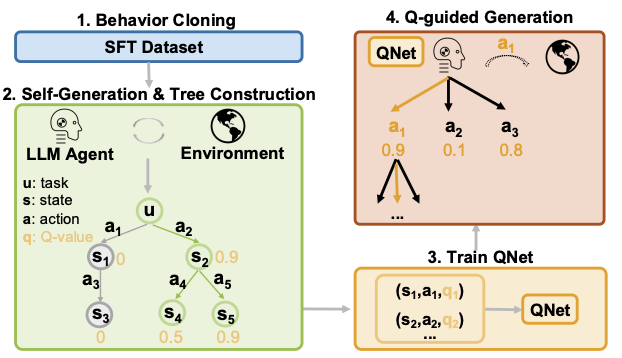
Zongyu Lin*,Yao Tang*, Xingcheng Yao*, Da Yin*, Ziniu Hu, Yizhou Sun, Kai-Wei Chang *Equal Contribution ICML 2025 preprint, code Interested in the combination of Inference time scaling + LLM Agent?🤖💭 Announcing QLASS (Q-guided Language Agent Stepwise Search), a framework that supercharges language agents at inference time. ⚡In this work, we build a process reward model to guide open language agents on complex interactive tasks by estimating the Q-value of each step, without any human annotation for process rewards. |

|
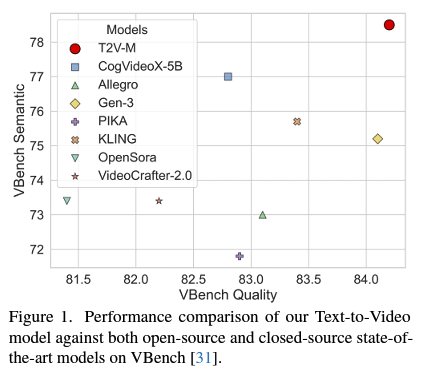
Zongyu Lin*,Wei Liu*, Chen Chen, Jiasen Lu, Wenze Hu, Tsu-Jui Fu, Jesse Allardice, Zhengfeng Lai, Liangchen Song, Bowen Zhang, Cha Chen, Yiran Fei, Yifan Jiang, Lezhi Li, Yizhou Sun, Kai-Wei Chang, Yinfei Yang *Equal Contribution ICCV, 2025 preprint, huggingface (#1 Paper of the day) Apple's latest recipe and studies for scalable video generation models🔥🔥🔥. In this work, we aim at providing a transparent and detailed recipe 📖 for model architecture, training strategy and data for scalable text-image conditioned video generation. The pretrained T2V and TI2V models outperform SOTA open-sourced, close-sourced models like Gen-3, PIKA, KLING and CogVideoX-5B on VBench. |
|
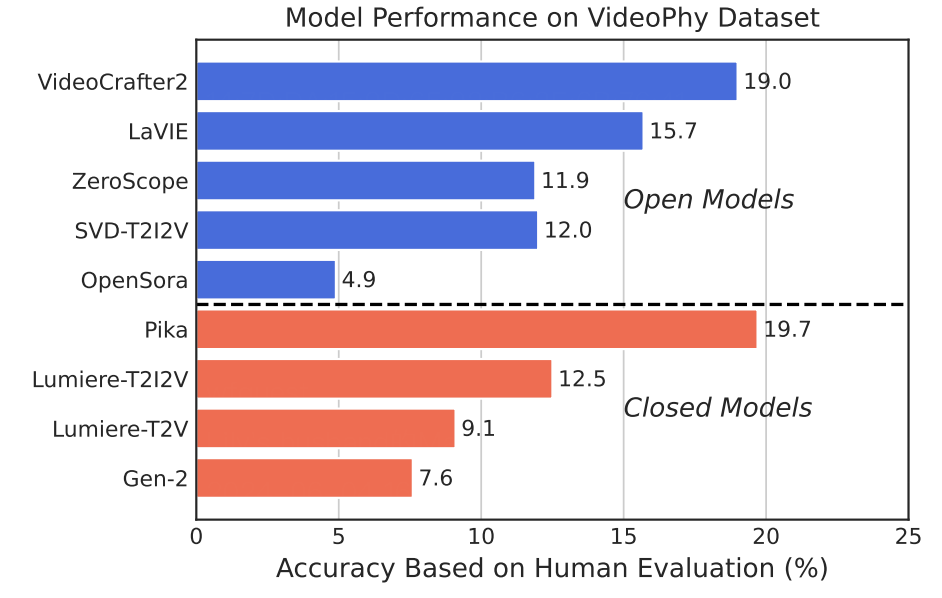
Hritik Bansal*, Zongyu Lin*, Jing Zhou, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, Aditya Grover *Equal Contribution ICLR 2025, Oral paper accepted by VL@NIPS, 2024 preprint, website, code We present VideoPhy, a benchmark designed to assess whether the generated videos follow physical commonsense for real-world activities (e.g. marbles will roll down when placed on a slanted surface). Specifically, we curate a list of 688 captions that involve interactions between various material types in the physical world (e.g., solid-solid, solid-fluid, fluid-fluid). |
|
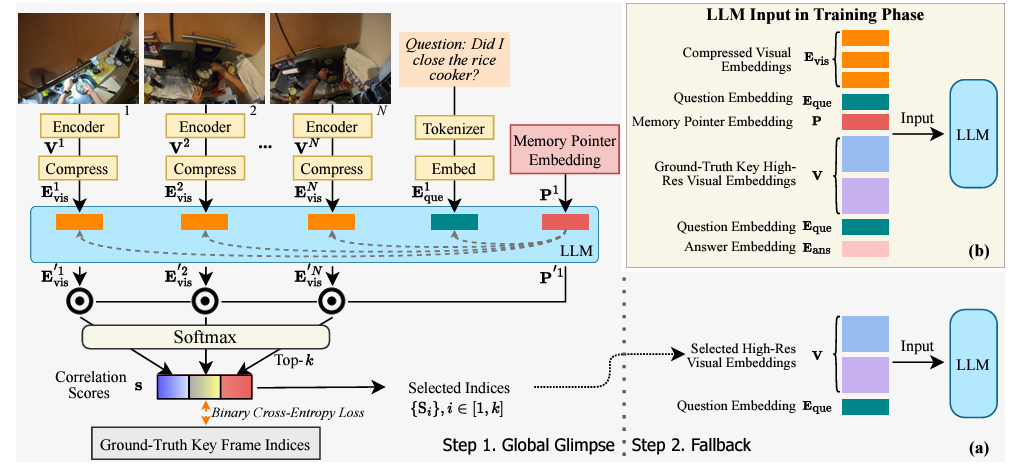
Hanrong Ye, Haotian Zhang, Erik Daxberger, Lin Chen, Zongyu Lin, Yanghao Li, Bowen Zhang, Haoxuan You, Dan Xu, Zhe Gan, Jiasen Lu, Yinfei Yang ICLR 2025 preprint This research aims to comprehensively explore building a multimodal foundation model for egocentric video understanding, covering training data construction, model and evaluation benchmark. |
|
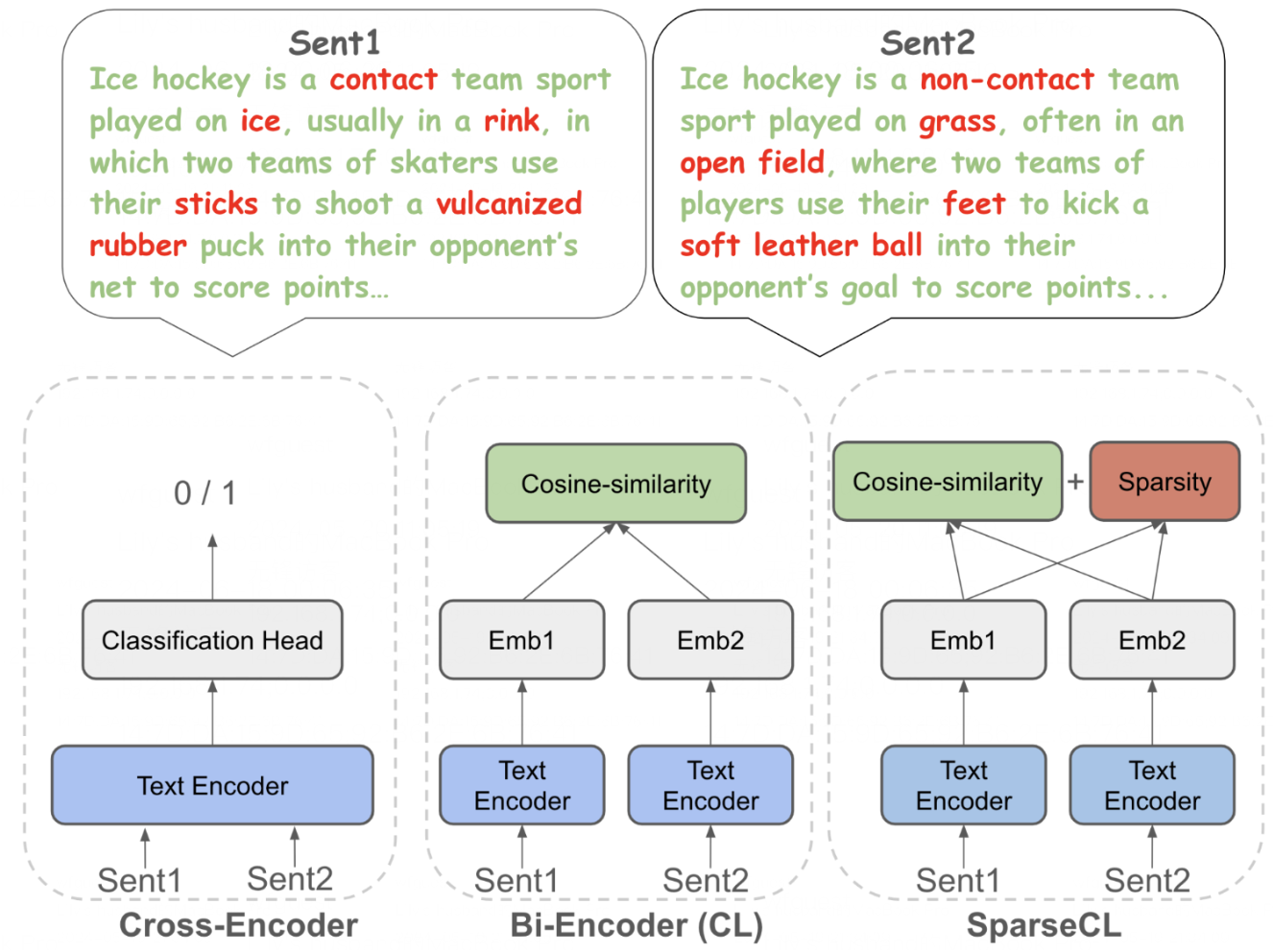
Haike Xu*, Zongyu Lin*,Yizhou Sun, Kai-Wei Chang, Piotr Indyk *Equal Contribution ICML 2025 preprint, website, code We propose a novel sparsity-aware contrastive method to solve contradiction retrieval problem, outperforming traditional bi-encoder and cross encoder baselines, which can benefit fact checking and pretraining data filtering. |
|
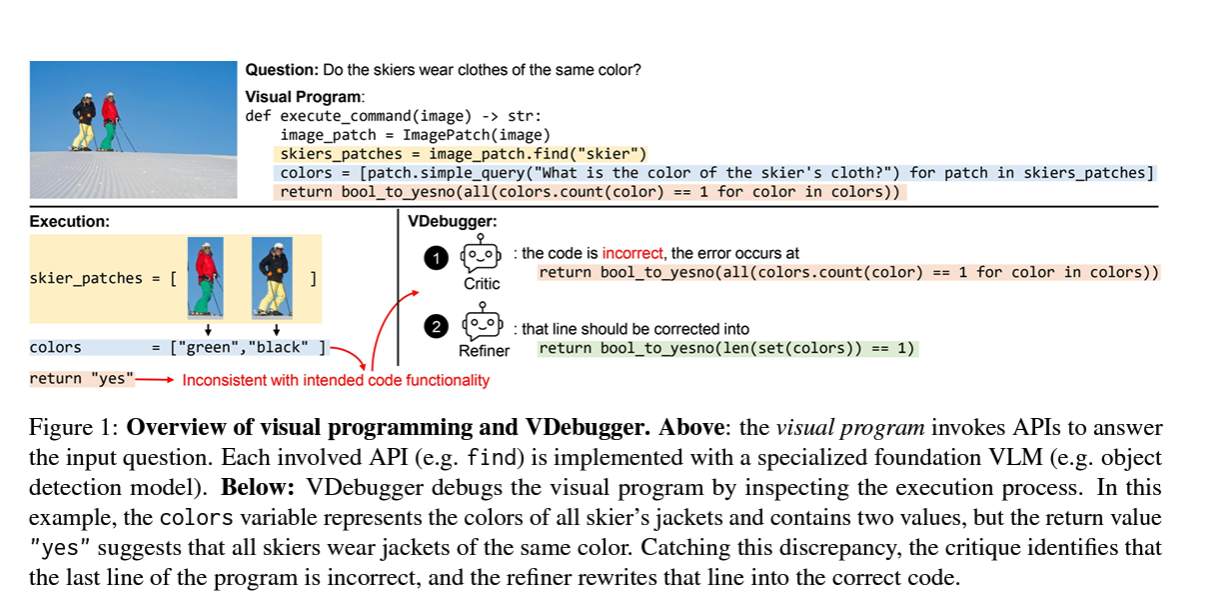
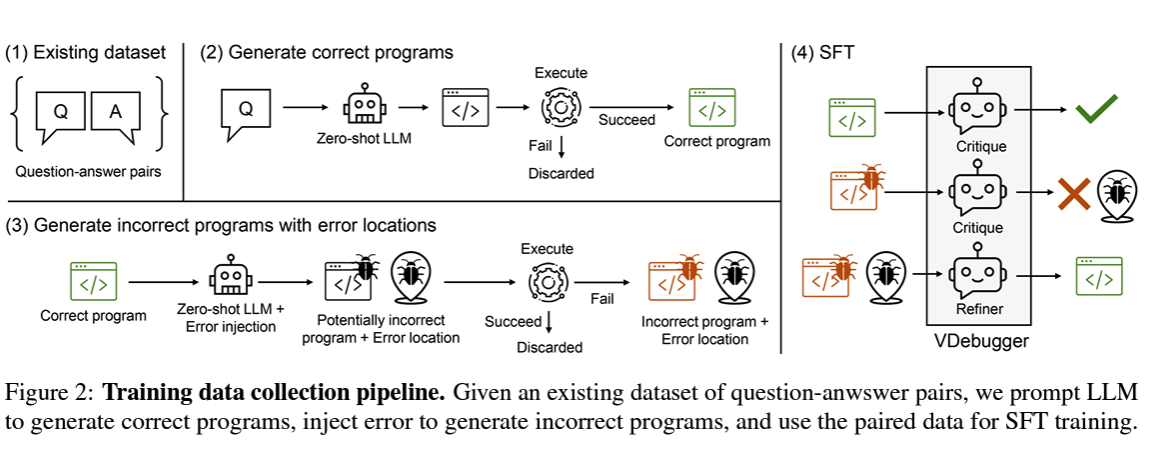
Xueqing Wu, Zongyu Lin, Songyan Zhao, Te-Lin Wu, Pan Lu, Nanyun Peng, Kai-Wei Chang EMNLP findings, 2024 preprint, code We train a generative judge (critique model) to improve visual programs of CodeLLMs. |
|
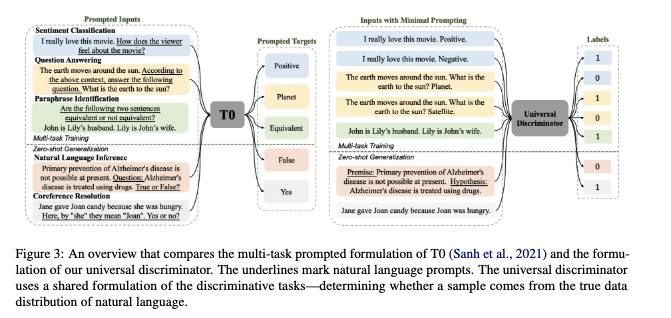
Haike Xu, Zongyu Lin, Jing Zhou, Yanan Zheng, Zhilin Yang ACL Oral, 2023 preprint, code We are the very pioneering work to study how to train the LLM as a reward model and study its zero-shot generalization on different NLP tasks. |
|
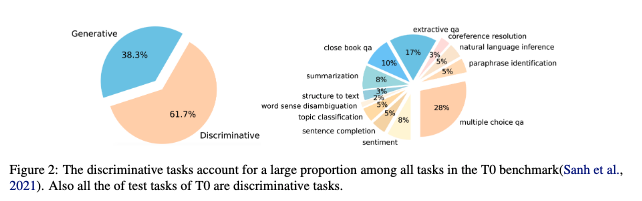
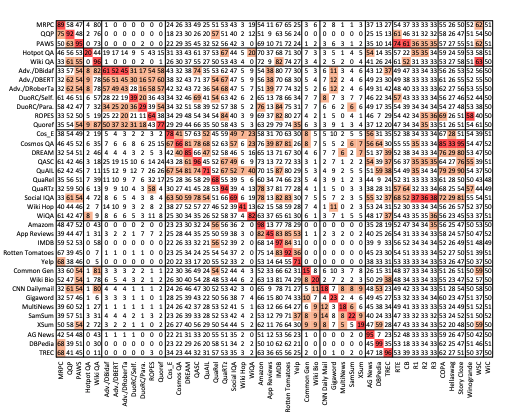
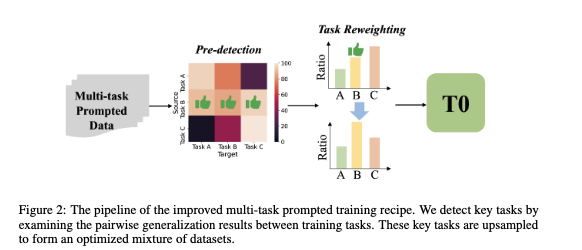
Jing Zhou, Zongyu Lin, Yanan Zheng, Zhilin Yang ICLR Spotlight, 2023 paper, code We are the very pioneering work to study the task transfer between different NLP tasks using LLMs. We propose several methods to improve the generalization of LLMs on zero-shot tasks from a data-centric perspective. |
|
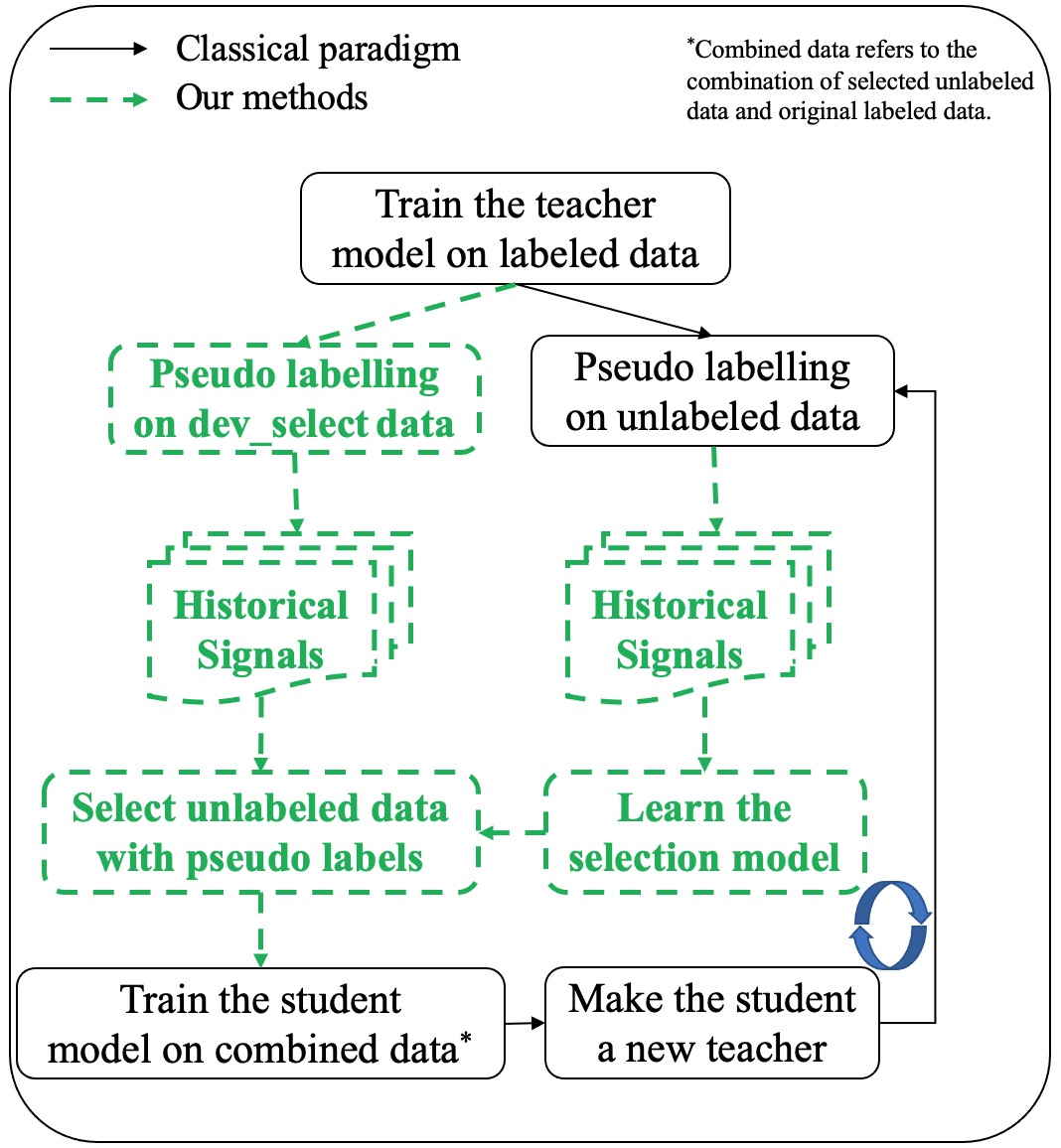
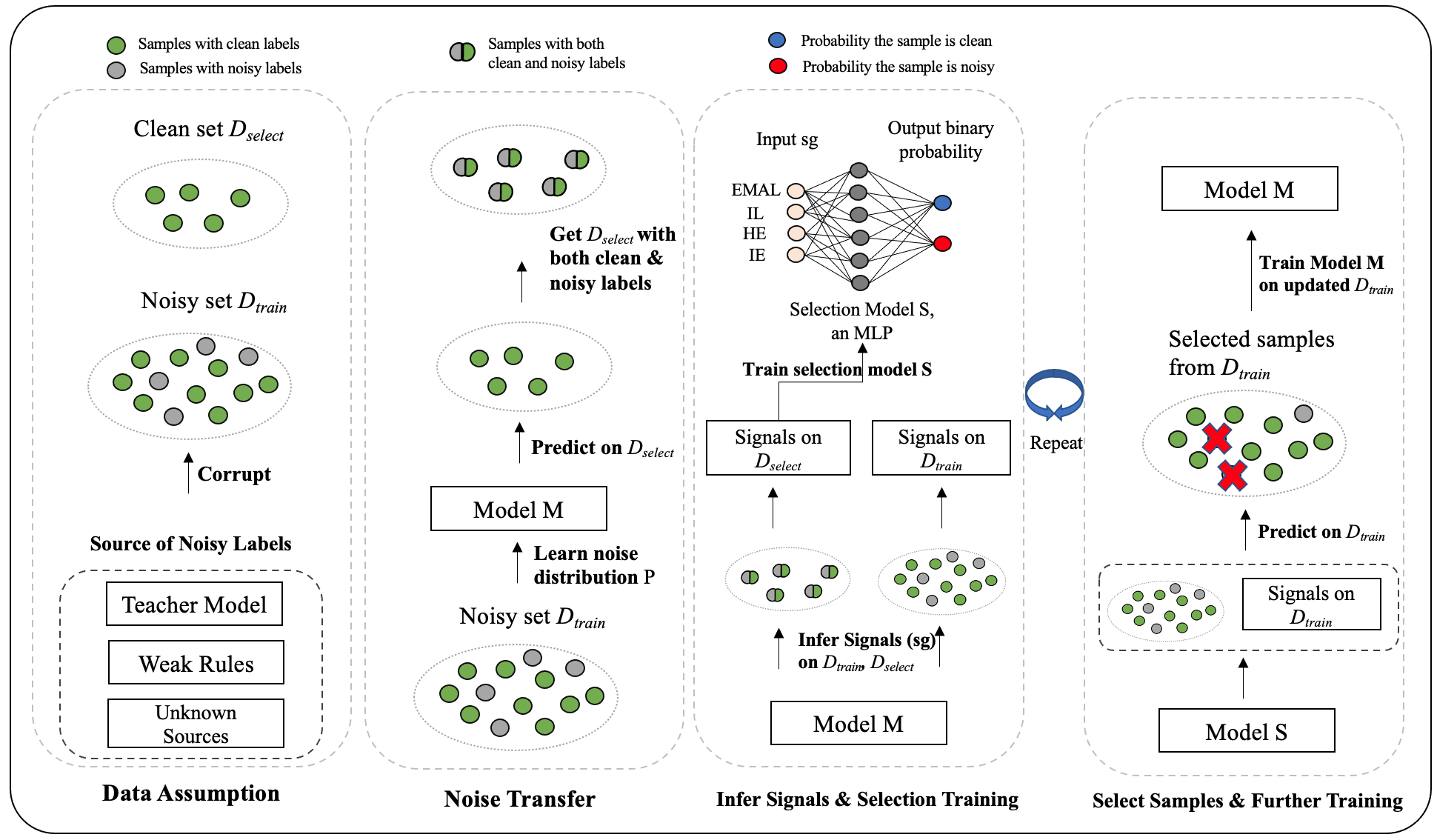
Zhihao Wang*, Zongyu Lin*, Peiqi Liu, Guidong Zheng, Junjie Wen, Xianxin Chen, Yujun Chen, Zhilin Yang (* First Co-Authors) Findings of EMNLP, 2023 preprint, code We are the early work to do self-training on LLMs, and we propose a novel model-based feature to detect noisy labels in the self-training process. |
|
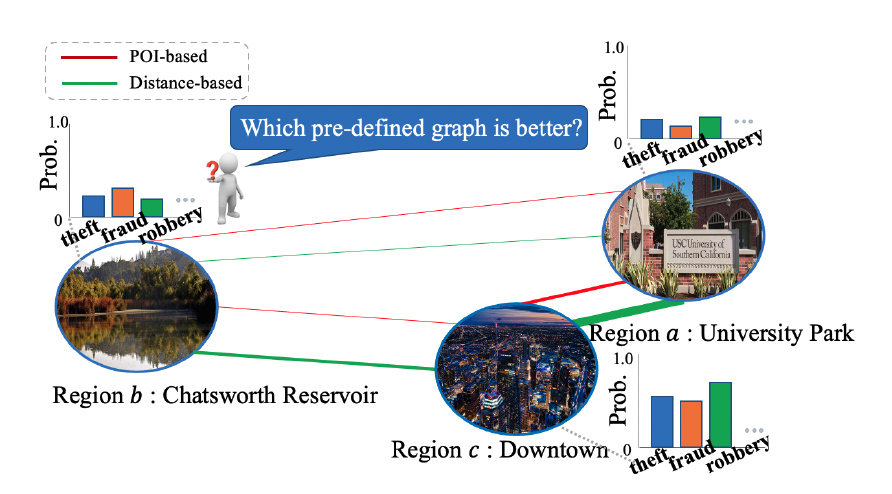
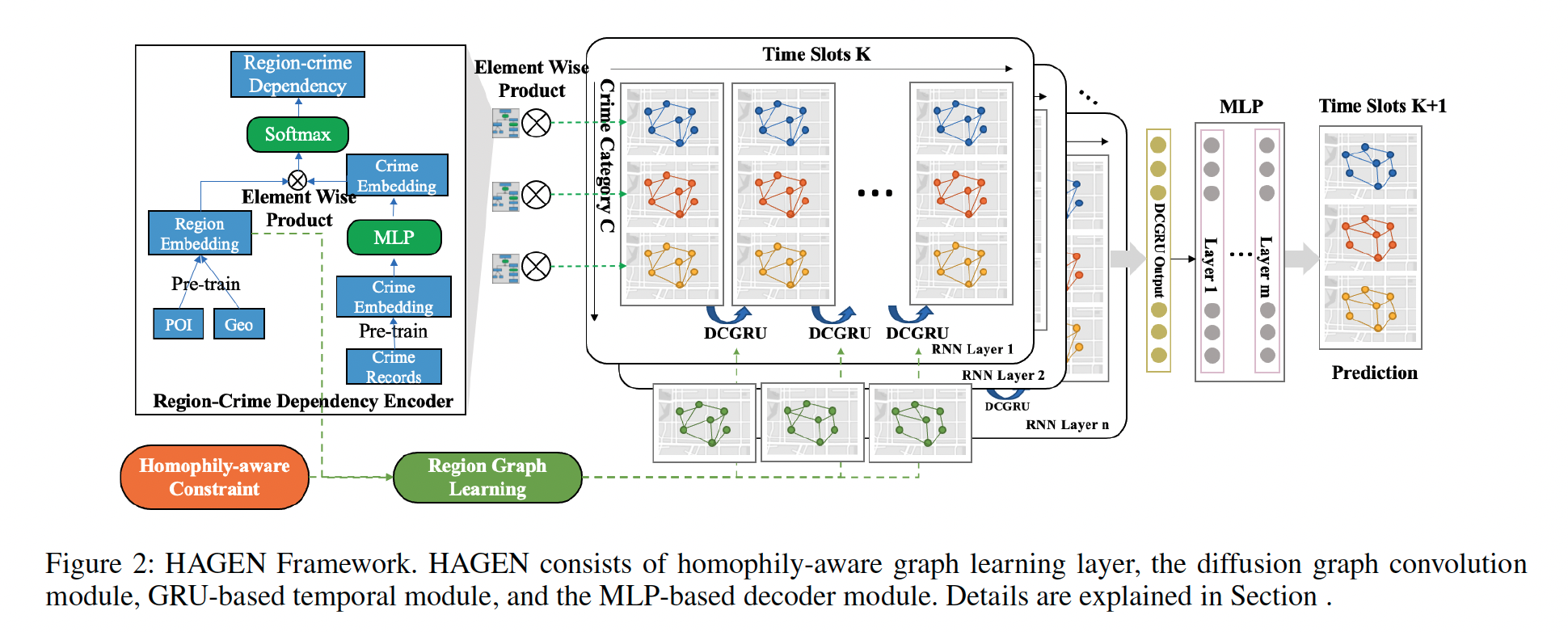
Chenyu Wang*, Zongyu Lin*, Guozhen Zhang, Xiaochen Yang, Jiao Sun, Mingxuan Yue, Cyrus Shahabi (* First Co-Authors) Proceedings of the AAAI Conference on Artificial Intelligence, 2022 paper, code We propose an end-to-end graph convolutional recurrent network called HAGEN with several novel designs for crime prediction. Specifically, our framework could jointly capture the crime correlation between regions and the temporal crime dynamics by combining an adaptive region graph learning module with the Diffusion Convolution Gated Recurrent Unit (DCGRU). Based on the homophily assumption of GNN (i.e., graph convolution works better where neighboring nodes share the same label), we propose a homophily-aware constraint to regularize the optimization of the region graph so that neighboring region nodes on the learned graph share similar crime patterns. |
|
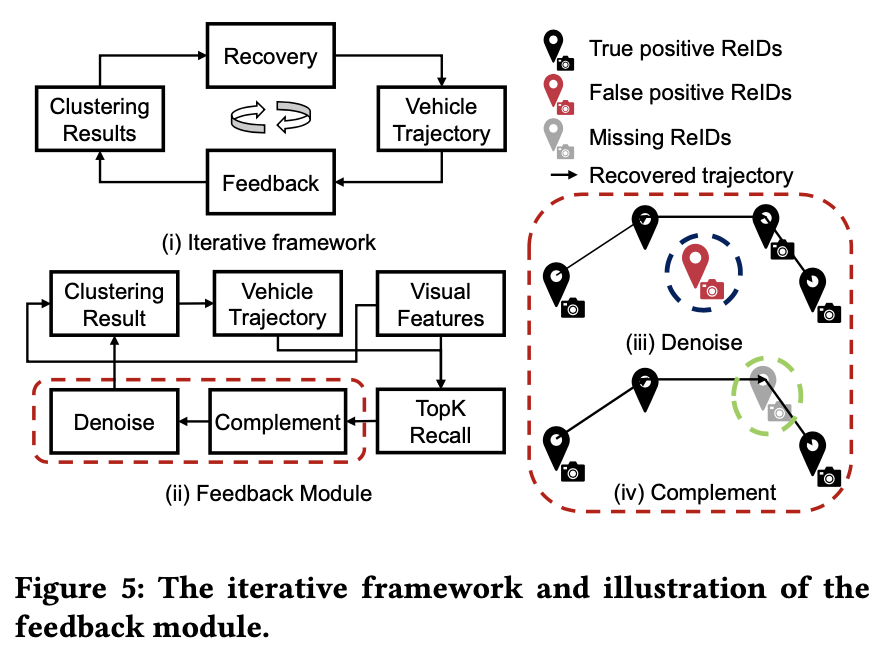
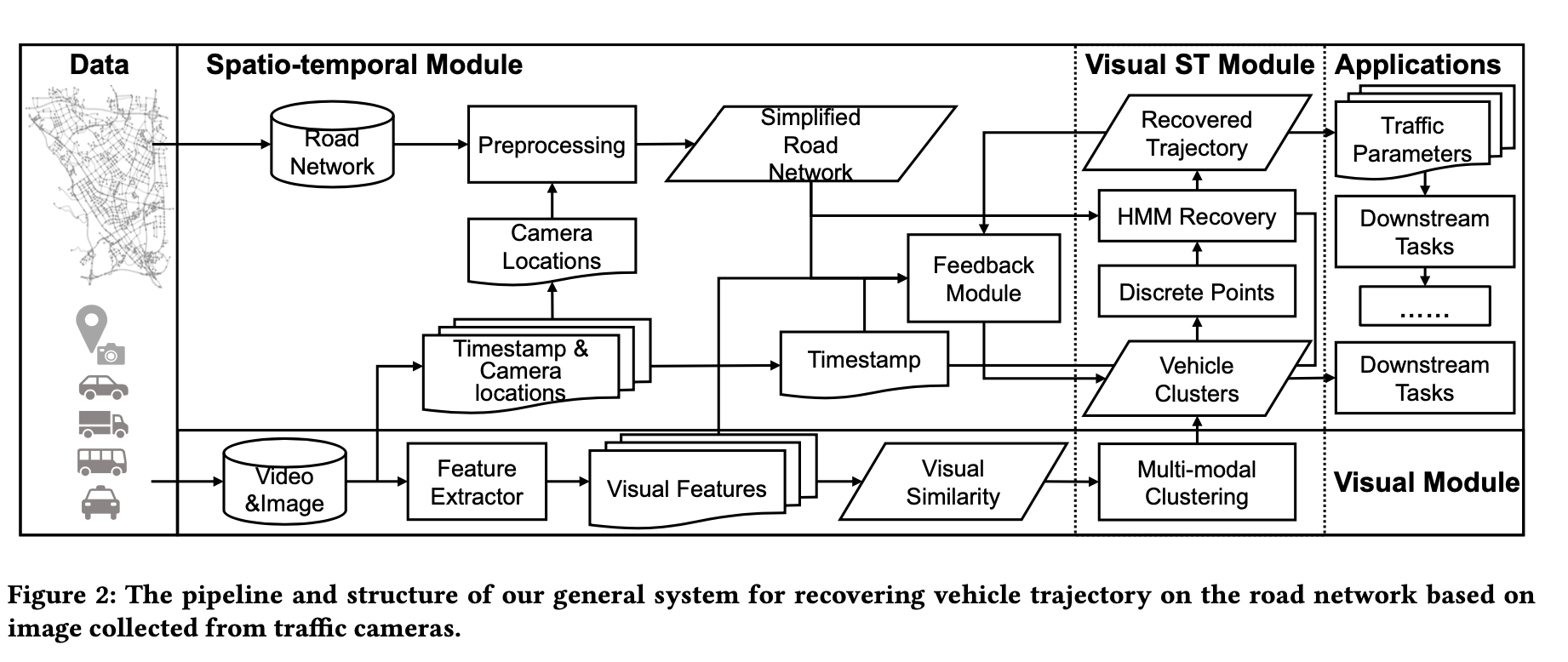
Zongyu Lin, Guozhen Zhang, Zhiqun He, Jie Feng, Wei Wu, Yong Li Proceedings of the 29th International Conference on Advances in Geographic Information Systems, 2021 paper We propose a general system to recover vehicle trajectories at the level of the road intersection, where a novel iterative framework is developed to combine both vehicle clustering and trajectory recovery tasks. |
|
Comprehensive Outstanding Scholarship(~10/280), Tsinghua University. 2020 Excellent Technology Innovation Scholarship, Tsinghua University. 2020 First Prize in Software Design Contest, Department of Electronic Enginnering, Tsinghua University. 2018 |
|
Teaching Assistant • Natural Language Processing Seminar(Spring 2022). Teaching assistant. Instructor: Prof. Zhilin Yang. Tsinghua University
Mentoring • Xiaohan Song (2024), undergraduate at UCLA • Yao Tang (2024), undergraduate at SJTU, now a PhD at UPenn • Guang Yang (2022), undergraduate at Tsinghua University, now a PhD at UW • Haike Xu (2022), undergraduate at Tsinghua University, now a PhD at MIT • Chenyu Wang (2021), undergraduate at Tsinghua University, now a PhD at MIT
Reviewer • 2025: ICML, ICLR, ACL, NeurIPS • 2024: NeurIPS, ACL, EMNLP • 2023: ACL, EMNLP
|
|
Sports! I really enjoy playing ballgames like football and tennis. I am a big fan of Lionel Messi, Rafael Nadal and Stephen Curry! Also, I love running, swimming and hiking. |
Updated at June.2024. Thanks Jon Barron for this concise and beautiful template.